|
تحلیل داده ها
از تحلیل رشد طبقه پنهان(LCGA) که روشی برای داده های طولی است و فرض می کند که متغیر پنهان شامل چندین طبقه/گروه است برای شناسایی الگوی مسیرها در امتیازات کل مشکلات SDQ در چهار نقطه زمانی استفاده کردیم. از یک برآوردگر MLR نیز استفاده شد. پس از برازش مدل یک طبقه ای، تعداد طبقه های مسیر بهطور متوالی افزایش یافت تا اینکه بهترین برازش مدل را مطابق با تحلیلها با استفاده از معیار اطلاعات بیزی(BIC)،BIC تعدیلشده(ABIC)، آنتروپی، آزمون نسبت درستنمایی Lo-Mendell-Rubin (LMR-LRT) و آزمون نسبت درستنمایی خود راه اندازی(BLRT) برای تعیین تعداد طبقه های پنهان پیدا شود. LCGA را برای نمرات خرده مقیاس SDQ نیز انجام دادیم. علاوه بر این، LCGA دیگری را در 1291 کودک با امتیازات کل مشکلات DCDQ زیر نقطه برش (بالاتر از نمره برش) به عنوان یک گروه بدون مشکلات هماهنگی حرکتی انجام دادیم. به عنوان یک تجزیه و تحلیل حساسیت، LCGA را برای 802 کودک، دوباره تجزیه و تحلیل کردیم و تأیید شد که ساختار طبقه و نسبت کودکانی که به هر طبقه اختصاص داده شده بودند، مشابه نمونه اولیه (773 کودک) بود.
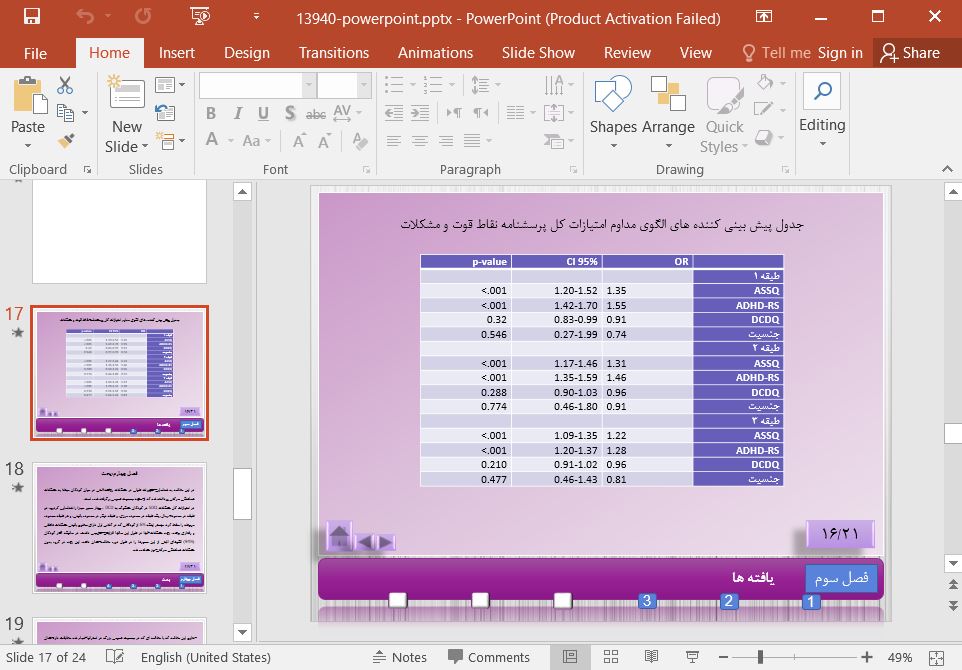
سپس تحلیلهای رگرسیون لجستیک چند جملهای را با امتیازات کل برای ASSQ و ADHD-RS به عنوان متغیرهای مستقل انجام دادیم تا تأثیر ویژگیهای ASD و ADHD را بر روی الگوهای پیش آگهی دهنده ضعیف مشکلات عاطفی و رفتاری بررسی کنیم. برای تعدیل اثرات اخلالگر احتمالی، امتیاز کل DCDQ و جنسیت نیز به عنوان متغیرهای مستقل در نظر گرفته شدند. از یک رویکرد تخمین سه مرحله ای استفاده کردیم. در این رویکرد، مدل طبقه پنهان در گام اول تنها با استفاده از متغیرهای شاخص طبقه پنهان برآورد شد. در مرحله دوم، شرکت کنندگان بر اساس محتمل ترین احتمالات پسین به هر طبقه اختصاص داده شدند. در مرحله سوم، با در نظر گرفتن خطای اندازهگیری مربوط با محتملترین عضویت در طبقه، عاملی از محتملترین طبقه بر روی متغیرهای پیشبینیکننده کنار گذاشته شد.
|